Все мы знаем, что такое 3D-принтер -- спасибо журналистам! Некоторое время назад имел место бум 3D-принтеров, такой громкий, что почти 3D-бум. Заметки на эту тему Остап Бендер мог бы использовать для своего пособия по сочинению "... парадных стихотворений, од и тропарей" -- помните? Каждый радостно делал свое дело -- изготовители получали стартовый капитал, и привозили на выставки то, что удавалось сделать, потребитель потреблял восторженные статьи, журналисты обслуживали тех и других, но более всего -- свои издания, поднимая читабельность и кликабельность. Мало кто написал очевидное: дорогущая технология, конкурентная только для одиночных деталей из вполне определенных материалов, почти исключительно -- из пластиков. Любимый слоган был "... но начало положено", а некоторые писали совсем смешное, например: "метод хорошо подходит для создания моделей, не предназначенных для высоких механических нагрузок и не требующих высокой износоустойчивости -- например, ювелирных изделий" или "участники стартапа хотят научиться печатать съедобные биоматериалы. Что же, начинание благородное, которое, возможно, решит проблему некоторых голодающих стран". Самые отчаянные фантазировали на тему принтеров, которые сами принтят принтеры, не понимая, что оный принтер без управляющего компьютера -- просто кучка деталек.
Трезвые отзывы бывали, например, в "Компьютерре" (old.computerra.ru/vision/731652/) и в "Химии и жизни" (2014, N 12). Резюме звучало примерно так: для художественного творчества в домашних условиях -- да. Для имплантов и эндопротезов в медицине, где также многое индивидуально -- тоже да; но все остальное очень проблематично. Потому, что техника, использующая сотни одних только сталей, тысячи сплавов и десятки тысяч материалов, не захочет отказываться от этого разнообразия.
Несколько десятков лет назад похожая история приключилась со сверхпластичностью. Было обнаружено, что некоторые сплавы при некоторых условиях (температура, скорость деформации) могут деформироваться в десятки раз (ну, как пластилин) при относительно небольших усилиях. Тут же началось: завтра все станки на помойку, учебники по металлообработке -- букинистам, все будем делать только этим способом. Потом выяснилось, что механизм проявляется лишь для некоторых сплавов и при тонко подобранных условиях. Позже энтузиасты список материалов, конечно, расширили, но до традиционной универсальности литья, резания, штамповки и сварки все равно -- как до Марса.
Еще одна история этого типа -- порошковая металлургия, изготовление деталей прессованием (обычно -- с нагревом) из порошка. Плюсы и минусы очевидны, и в итоге технология заняла свое место среди великого множества созданных людьми технологий. Но поначалу была сильная вспышка энтузиазма и надежд.
По-видимому, это просто психология: человеку хочется чего-то простого, универсального, могущественного... то есть волшебного. Это свойство ехидно отрефлектировано массовым сознанием в виде анекдота: "У проблемы есть два решения, фантастическое -- мы сами сделаем, и реалистическое -- прилетят инопланетяне и помогут".
Параметры для сравнения
Когда мы пытаемся понять, как изменяется мир вокруг нас, мы сравниваем значения параметров. Например, за какое время мы можем попасть из Москвы в Нью-Йорк (и, разумеется, обратно) в XVIII, XIX, XX веке? Сейчас и через 7 лет, когда взлетит сверхзвуковой Aerion? Сколько нужно времени, чтобы найти дешевый билет с учетом дней вылета и прилета, удобства стыковок? Сколько времени занимает покупка и регистрация? Заметим, что Интернет и компьютеры радикально изменили ситуацию в части этих пунктов.
Когда мы сравниваем все, имеющее к нам отношение -- качество и стоимость еды, безопасность и прожорливость автомобилей, скорость движения по дорогам и наличие парковок, стоимость образования и его влияние на будущие доходы -- мы всегда оперируем внешними, потребительскими параметрами. При этом потребителя, и это естественно, мало интересуют внутренние параметры -- стоимость разработки, количество проведенных испытаний, совершенство элементов, количество патентов, защищающих конструкцию и технологию и так далее. Но -- за одним замечательным исключением.
Читатели упиваются данными о скорости компьютеров и объеме их памяти, не спрашивая -- а как это влияет на стоимость авиабилетов и время регистрации? В некоторых случаях ситуация очевидна -- до определенного уровня влияние было, а дальше его не стало, потому что выдаваемые компьютером результаты все равно должен осознать человек. И будет компьютер предлагать нам вариант за 1 сек или за 0,1 сек -- не важно. В некоторых случаях связь сложнее, но она хоть может быть прямо указана -- было бы желание. Метеорологи говорят, что точность прогноза зависит от мощности компьютера, на важность компьютерного моделирования указывают и разработчики лекарств. В этих случаях возможен, в принципе, четкий ответ -- применение такого-то компьютера повлияет на точность прогноза вот так, а на время разработки лекарства -- вот этак.
Наконец, есть случаи, когда увеличение мощности компьютеров важно для более "внутренних" частей задач, и тогда объяснить не профессионалу, зачем это нужно, делается трудно. Это гидро- и аэродинамические расчеты, расчеты при разработке термоядерного боезаряда, процессы в недрах планет и звезд, расчеты структур и свойств в химии. Во всяком случае, если мы хотим не просто ахать (и охать), а еще и что-то понимать, имеет смысл иногда спрашивать -- зачем нужны петабайты, как и на что они повлияют.
Определение
В публикациях, так или иначе посвященных "big data" или "большим данным", авторы начинают с попытки определения и называют какие-то из следующих признаков:
- нужно работать с большим количеством данных;
- причем заказчик честно предупреждает, что объем будет расти;
- данные нужно обработать быстро;
- в некоторых случаях не вообще быстро, а именно в темпе поступления;
- данные могут храниться в разных местах или поступать из разных мест;
- информация может быть структурирована по-разному или "не структурирована";
- результатом работы программы должна быть инструкция для человека.
Первые пять признаков понятны, задачи, наделенные этими признаками, встречались и ранее, признаки могли сочетаться. Новизна состоит в том, что предполагается увеличение количества данных на несколько порядков и постулируется, что это потребует разработки новых программных средств. Иногда произносятся какие-то слова про скорость нарастания, журналисты и рекламщики очень любят слово "экспоненциально". Знают ли они его смысл и понимают ли, что его применение в данной ситуации некорректно? Но слово красивое. Что касается реальности, то новые способы обработки информации предлагались, и соответствующие программные продукты есть на рынке. Действительно, увеличить что-либо на порядок и более старыми способами обычно не удается.
Со структурированностью дело сложнее: имеется в виду, что данные, относящиеся к одному и тому же объекту, могут поступать в совершенно разной форме. Например, мы собираем информацию о человеке -- тогда это информация о платежах (когда, сколько, кому), о занятиях (чем, с кем, когда, сколько), о настроении (частота звонков приятелям, лексика в электронной переписке, заполнение поля "настроение" в социальных сетях, что насвистывал, идя по улице), съемки с камер видеонаблюдения, фотки (свои и котиков), которые он вываливает в Интернет. Тут и цифры -- суммы и времена, и имена людей, и названия дел по непонятно какой классификации, и записи мелодий, фото- и видеофайлы . Так что над приведением не числовых данных в числовую форму еще придется попотеть, несмотря на кондиционер в офисе, но компьютерщики со многими из этих задач справляются - например, с распознаванием по фото. Космическая и не космическая разведка распознаванием занимается очень давно и очень тщательно.
Почему же был такой экстаз... примерно такой же, как в истории с 3D-принтерами? Наверное, важно короткое, звучное, легко запоминающееся имя. Далее -- цепляющий образ, лучше всего -- визуальный. Что такое принтер, знают все; и вот он будет печатать объемное: непонятно как, но круто! Сталь как пластилин -- здорово! Слепил куличик из порошка -- и готовая деталь! А big data -- это что-то большое, не важно что, но большое -- тоже очень хорошо.
Огромные массивы данных, причем поступающие с высокой скоростью, встречались человечеству и раньше. Наверное, самый "большой" пример -- это потоки данных с больших телескопов и с детекторов больших ускорителей. Объем данных там такой, что вопрос о хранении вообще не встает, то есть надо в реальном времени отбирать наиболее интересные события. И вот тут возникает принципиальная разница с идеологией big data -- отбор данных для хранения требует понимания происходящего. Именно так устроена вся наука -- она строит модели по мере познания, и процесс получения данных вообще управляется уже имеющимся знанием. Все научные приборы и все методы получения знаний базируются на уже имеющемся знании. У большинства идеологов big data подход противоположный -- они соблазняют менеджеров тем, что знать ничего не нужно -- навалим большую кучу данных и программа не только сама найдет, но и даже скажет, что делать.
В науке действительно сплошь и рядом при исследованиях и измерениях обнаруживается нечто новое и непредусмотренное -- это важный источник развития. Но опять же -- это обнаруживается там, где ищем, теми приборами и методами, которые созданы на основе того, что уже известно. Тут возникает метанаучный вопрос о соотношении нового и известного и об ограничениях на новое, возникающих из-за неизбежного пользования старым. Интересный вопрос, и про конкретные исторические ситуации можно, наверное, указать, как имеющееся знание на конкретном этапе повлияло на получение нового. Впрочем, иногда пишущие о big data все-таки робко указывают, что все-таки лучше понимать, что и как делает могучая программа. Но они среди пишущих -- в меньшинстве.
Еще один признак трезвого мышления -- указание на то, что наличие большого количества бесплатных данных позволяет сэкономить на исследованиях. Да, конечно, если среди этих уже имеющихся данных найдутся нужные, или такие, из которых можно эти нужные извлечь. Но для этого как раз и надо понимать, что и зачем мы ищем.
Способы задеть подсознание
Для раскрутки любой идеи желательно, чтобы она задевала что-то в человеке. Идея 3D-принтера способна задеть в человеке минимум четыре мотива, вот первые три -- "сделай сам", желание спихнуть на другого и желание игры. Взрослому дяде играть в игрушки немного странно, но ведь хочется -- а тут такая социально приемлемая возможность. Что касается "сделай сам" и желания спихнуть на другого, то они, скорее всего, гнездятся в разных людях. Сочетание "сделай сам" и желания игры привлекло в первую очередь тех, кому не чуждо стремление сделать что-то самому, сконструировать, наладить и т. п., и это ускорило развитие области. Сочетание желания спихнуть и игры -- это, скорее, некоторые люди от искусства, которые готовы придумать замысловатое, но рубить мрамор лень. 3D-принтер не воспринимает фантазии расторможенного подсознания, но 3D-сканеры, воспринимающие движение, уже существуют, и наверняка будет создан прибор, облегчающий работу скульптора. Творец, вдохновенно двигая руками в воздухе (при этом на кончики пальцев надеты "метки", которые видит сканер), создает пространственное изображение, которое компьютер сначала показывает ему на экране (можно и в объеме), а потом отправляет для реализации на 3D-принтер.
Насчет big data ситуация такова -- из этих трех мотивов работает желание спихнуть: человеку кажется, что если мы соберем большую кучу данных, то волшебные программные системы сами (это ключевое слово -- сами) извлекут из помойки жемчужное зерно, во всем разберутся, и не просто разберутся, а скажут, что делать. А мы покровительственно похлопаем железку по плечику, скажем понятно кому принести кофе, нахмурим брови и примем решение. Человек принимает решение -- это звучит гордо! Промоутеры этих систем откровенно подсовывают потребителю эту мысль: "big data сами по себе не интересуют бизнес, надо сформулировать бизнес-задачу и продвигать работу по ее решению как бизнес-проект".
Судебные врачи в Австро-Венгерской империи на это бы ни разу не повелись. Помните: "- А вы могли бы вычислить диаметр земного шара? - Извиняюсь, не смог бы, -- сказал Швейк. -- Однако мне тоже хочется, господа, задать вам одну загадку, -- продолжал он. -- Стоит четырёхэтажный дом, в каждом этаже по восьми окон, на крыше -- два слуховых окна и две трубы, в каждом этаже по два квартиранта. А теперь скажите, господа, в каком году умерла у швейцара бабушка? Судебные врачи многозначительно переглянулись".
Осторожные авторы пишут, что человек, пользующийся моделью, должен понимать, как она работает, что в нее заложено. Но об этом не пишут те, кто радостно продвигает свой продукт -- им важно, чтобы купили. Вот на всякий случай два примера эффективности применения именно мозга. Весьма эффективный анализ хорошо структурированных данных можно увидеть в Интернете с помощью поискового запроса "математика выборов" (для первого знакомства в "инструменты" ставить "за год"), а также "готовимся к голосованию 2016 года". Противоположную ситуацию, то есть весьма эффективный анализ плохо структурированных данных, можно увидеть с помощью поискового запроса "Bellingcat".
Петух и куча
При увеличении количества обрабатываемых данных и "глубины обработки", то есть количества проходов через мясорубку, действительно увеличивается вероятность "подметить" какую-то закономерность. Представим себе, что мы измеряем некий параметр в течение месяца, каждый раз фиксируя его рост или спад по отношению к предыдущему дню, и сопоставляем с ростом или спадом продаж определенного продукта на следующий день. Исследовав таким образом всего лишь 10 миллиардов случайных параметров, мы наверняка обнаружим параметр, который точно предсказывает наши продажи. И пусть вас не пугает число 10 миллиардов -- в данном случае все данные займут всего ничего по меркам big data -- 40 Гб. Повторяю -- мы найдем чудовищно убедительную корреляцию (месяц -- ежедневно, ни одной осечки!) с заведомо случайным параметром. И не подумайте, что нам потребуется так много независимых параметров: если их комбинировать (опять же, случайным образом), полутора десятков хватит и еще останется. А можно просто обойтись датчиком случайных чисел...
Это рассуждение тривиально и "количественно", а вообще-то тезис о том, что корреляция не означает зависимости -- азы социологии. Однако универсального решения -- как отличить одно от другого -- увы, нет. Точнее, оно есть только в естественных науках, и то -- лишь асимптотическое. Но апологеты big data этого не знают и радостно пишут, что мы вступаем в эпоху, когда важны только корреляции, а зависимости не важны. Трудно придумать более фундаментальное утверждение. Остановитесь и вдумайтесь: это не "новое слово в науке", это новое слово вместо (прописью -- вместо) всей науки.
Некоторые промоутеры, всерьез и не краснея, пишут, что "в среднем мировой рынок технологий и услуг для больших данных будет демонстрировать до 2019 года устойчивый рост -- порядка 23,1%. В 2019-м его объёмы составят $48,6 млрд. Среднегодовой рост сегмента инфраструктуры за период 2014-2019 составит 21,7%. Сегмент программного обеспечения для обработки big data вырастёт на 26,2%. Наконец, объём рынка услуг, связанных с большими данными, возрастёт на 22,7%". Точность предсказания порядка 0,1% -- это восхищает, гипнотизирует, открывает сердца и даже кошельки. А разве не гипнотизирует фраза "более века назад физики предположили, что не атомы, а информация является настоящей основой всего сущего"? Или вот прелестная фраза: "Вероятность же того, что после просмотра персонализированной рекламы люди перейдут к действиям (купят ту или иную вещь или проголосуют за нужного кандидата) возрастает на 1400%". У человека, который пишет такое, кажется, что-то не в порядке с его data.
Проблема замусоривания результатами обработки возникла намного раньше big data. Например, социологические данные стандартно обрабатывают могучим программным пакетом SPSS (800 Мб на жёстком диске). Чего там только нет! Если трудолюбиво крутить ручку этой великолепной мясорубки, то можно получить большое количество результатов, среди которых могут найтись связи, в реальном мире ничему не соответствующие. Возникает вопрос -- докуда зарываться в обработку в этой и подобных ситуациях? Возможное решение вот -- по мере обработки данных сначала мы получаем тривиальные результаты, очевидные и понятные без компьютера. Потом начинают появляться результаты, которые предсказать трудно или невозможно, но когда они получены, исследователь на них посмотрит, подумает и скажет -- "ну, это можно понять вот так...". Потом начнут появляться результаты, про которые он подумает и... промолчит. Допустимая доля таких результатов в публикации -- вопрос традиции: физики тут строже социологов. Но доля эта всегда не равна нулю -- то, что не понял я, может понять мой коллега, читая статью. Но и слишком большой она быть не может -- рецензент скажет, что автор поленился с анализом, и редактор попросит статью доработать. То есть норма поддерживается отчасти внутринаучной, отчасти же -- общесоциальной традицией. Ибо, в конечном счете, науку содержат техника и экономика, и ее нормы связаны с ее успешностью, которую и определяют техника и экономика.
Вообще же разделение на обработку данных и понимание результата -- конечно, упрощение. Нормальный ученый всегда ведет обработку с использованием уже достигнутого понимания. Но если меня сначала убедили, что "возрастет на 22,7%" и спасет мою фирму, а потом пригрозили, что будет такой big, что я сам не смогу понять, то самая пора вздохнуть облегченно, открыть кошелек и довериться программе.
Дальнейшая история
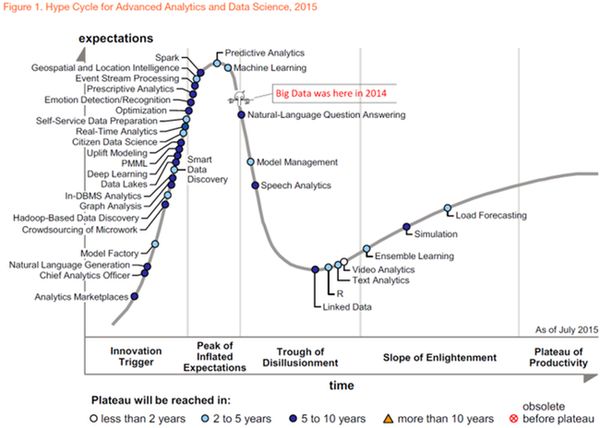
Один их способов бесплатно оценить перспективы той или иной информационной технологии -- это заглянуть на сайт фирмы Gartner или поискать в Интернете их материалы и ссылки на них (запрос в Интернете -- Gartner). Это исследовательская и консультационная компания, специализирующаяся на рынках информационных технологий. Фирма известна введением в практику методов исследований и регулярными исследованиями рынков информационных технологий и аппаратного обеспечения. Они вообще полагают, что нормальный цикл состоит из вспышки интереса, спада и -- либо смерти, или медленного, спокойного и закономерного роста. Для примера вот график за 2015 год http://www.globalcio.ru/workshops/1358/
Так вот, осенью 2015 года стало известно об исключении из отчета Gartner "Цикл зрелости технологий 2015" сведений о big data. Исследователи объяснили это размыванием термина -- входящие в понятие "большие данные" технологии стали повседневной реальностью бизнеса. А аналитики компании - тем, что в состав понятия "большие данные" входит большое количество технологий, активно применяющихся на предприятиях, они частично относятся к другим популярным сферам и тенденциям и стали повседневным рабочим инструментом. Это -- рациональный подход: психологией Gartner не занимается.
Четвертый всадник Апокалипсиса -- страх
Возможно, что в проблеме big data еще одна сторона. Главный заказчик высокотехнологичных продуктов -- тот, кто может за них платить, у кого есть деньги. В нормальной стране -- это торговля, ибо туда несет свои деньги конечный потребитель, человек. Если при анализе данных замечена корреляция, торговля, скорее всего, сумеет ею воспользоваться -- хотя бы для уменьшения запасов на складах и транспортных расходов. А ежели один из коррелирующих параметров управляем, то возникает соблазн проверить, нет ли тут функции и возможности извлечения дополнительного дохода. Увеличивая количество собираемой информации и приспосабливая рекламу к все более узкому кругу лиц, можно выйти на конкретного потребителя и предложить ему то, что он купил бы с наибольшей вероятностью -- в случае, если бы мы ему ничего не предложили. Выглядит эта система замечательно, но выше ли на самом деле вероятность покупки, чем в контрольной группе? Торговлю этот вопрос не интересует -- система уже куплена и поставлена, да и менеджерам развлечение.
Между тем, среди пользователей есть клиенты, которые предпочитают выбирать сами, благо по многим продуктам в том же Интернете есть профессиональные обзоры. Такого клиента реклама лишь раздражает, и более того -- он как раз скорее не купит рекламируемое, ибо понимает, что расходы на рекламу фирма в итоге вынет у него же из кармана. Он вообще будет сторониться фирмы, много тратящей на рекламу.
Торговле безразлично, кто именно купил вещь или услугу. Поэтому, вообще говоря, персональная идентификация для торговли не обязательна. Тем не менее, получение большого количества данных о каком-то конкретном человеке позволяет вычислить этого человека, даже если он не сообщал системе номера паспорта, прав, СНИЛС или ИНН. Более того -- где граница между простым предъявлением лучшего товара и манипуляцией? Предположим, система установила, что у клиентов, купивших товар А, покупка товара Б коррелирует с покупкой дорогого товара В. Чем будет предъявление товара Б? Не манипуляцией ли с целью впарить ему товар В?
Нормальный человек относится с настороженностью к государству -- даже если оно "ничего себе". Причин здесь две -- человек платит налоги, нанимает власть и желает, чтобы она эти налоги тратила разумно. Но правила, создаваемые системой, всегда более "общи", они не могут учитывать мелких частностей, а эта частность как раз и есть он -- конкретный налогоплательщик. Степень адаптации системы к человеку -- вопрос традиции, терпимости людей, типа их реакции (рабское терпение, взрыв и все по новой или же относительно плавная эволюция с колебаниями вокруг линии тренда), бедности и богатства -- богатое общество может создавать лучше адаптированные системы. Вторая причина -- совсем уж личная: человек знает по себе, как велик соблазн неразумно потратить легко полученное, и проецирует это на власть. Поэтому даже нормальному государству человек доверяет свои данные не слишком охотно, а уж авторитарному -- рад бы не доверять вообще.
А тут внезапно выясняется, что какие-то Гуглы и Яндексы все про нас знают! И уж мы-то понимаем, что государству они отдадут все по первому мановению пальчика. А некоторые сами прибегут впереди и паровоза, и "Сапсана" и будут объяснять власти, что все личные данные граждан -- это исконно и законно ее, Власти (не забыть книксен!), суверенная собственность (в надежде, что обломится заказ... заказы ведь не пахнут).
Немного о политике
В Интернете появилась информация о том, что некая фирма, собирающая и обрабатывающая данные о людях, помогла случиться "Брекситу" и Трампу (запрос в Интернете big data, Брексит, Трамп). Технология состояла в сборе информации о конкретных людях и либо в рассылке этим людям сообщений через соцсеть, либо в направлении к ним агитаторов, которые, по замыслу манипуляторов, должны были сдвинуть их выбор при голосовании. Крик, как всегда, был громок, но если посмотреть комментарии специалистов (а не "ведущих экспертов" -- по мнению ведущего шоу), общая оценка была сдержанная -- очень-де похоже все это на рекламу. На самом деле, ничего эпохального здесь нет, проблема лишь в одном -- в эффективности. А ведь ее можно и очень дешево измерить. Берем несколько пар округов, демографически и электорально близких, в одном из которых процедура проводилась, а в другом - нет. И вот у нас прогноз социологов и результат -- в экспериментальном округе и в контрольном: четыре числа, и все понятно. Пока такие данные не предъявлены, говорить не о чем. Да, лучше не четыре, а четырежды четыре.
"Из темноты портала выступил на высокую светлую паперть Адам Казимирович. Он был бледен. Его кондукторские усы отсырели и плачевно свисали из ноздрей. В руках он держал молитвенник. С обеих сторон его поддерживали ксендзы. С левого бока - ксендз Кушаковский, с правого - ксендз Алоизий Морошек. Глаза патеров были затоплены елеем. /.../ И началась великая борьба за бессмертную душу шофера".
Измерял ли кто-то вообще эффективность двух-трех писем или десяти минут разговора? Не нулевая ли она -- при проекции на действия, да через несколько дней? Не определяются ли действия колеблющегося избирателя или - шире - клиента вообще набором случайностей в последние пять минут перед голосованием или покупкой?
Что делать, если это не нравится?
Читать про big data иногда интересно, иногда забавно, но как раз нам -- не очень страшно. Экономическая ситуация такова, что покупка Ламборгини отложена до выхода из стагнации, а в "чего бы пожрать" мы и без рекламы разберемся. (Кстати -- стагнация... стагнация... нация... не это ли национальная идея, которую ищем?) Что до брекситов и хилларей с их трампами, то на результаты выборов в РФ заокеанским хакерам не повлиять, пусть бессильно скрежещут мышами.
Но если от запаха изо рта Большого Брата все-таки подташнивает, вот совсем простые шесть шагов к самому себе, настолько простые, что их сделал я:
- не пользоваться никакими социальными сетями;
- пользоваться анонимайзерами, в браузерах -- использовать правильные установки (приватные окна, защита от кукиз, защита от отслеживания, соответствующие плагины, это очень просто и в Интернете рассказано, как это делать);
- не оставлять следов на сайтах -- по возможности не регистрироваться, не комментировать, не оценивать, не лайкать, не отвечать на тесты, вопросы, опросы;
- после поиска в Интернете, но не реже, чем ежедневно, запускать бесплатный CCleaner;
- платить везде, где это возможно, налом, не нужно создавать в Интернете списки своих покупок и предпочтений;
- не пользоваться сотовой связью, для друзей есть домашний телефон, для службы -- служебный; не надо облегчать слежку за своими перемещениями и контактами.
Вы не поверите, но все это просто и экономит массу времени для чтения книжек и нормального общения с детьми и друзьями. Когда вы видите того, с кем общаетесь, видите его улыбку, слышите его голос.
И понимаете, что так же, как вы сейчас с ним, так и он сейчас с вами. А не с Интернетом.